A logical data model is defined in terms of the data model adopted by the DBMS package which will be used for the actual implementation. Regarding the software environment available, we will map a conceptual model to a CODASYL, relational or OO model. This mapping can be done automatically by a database modeling tool. Depending on the conceptual and logical data model selected, it is possible that we lose or add some semantics. They should be carefully documented, once again.
Mapping an EER model to a CODASYL model
This is an example where our conceptual model is richer, in terms of semantics, than our logical model. Hence, we will use semantics during the mapping. As a reminder, let’s briefly explain the two key concepts of the CODASYL model.
· A record type represents a set of records that consists out of data items. Vectors can be defined for multivalued attribute type and repeated groups can be used for composite multivalued attribute type. It can be owner and member in multiple set types.
· A set type describes a 1:N relationship between an owner record type and a member record type.
To map an EER model to a CODASYL model, we start by mapping every entity type to a record type. Atomic or composite attribute types can be directly supported in the CODASYL model. Multivalued attribute types can be modeled by vectors or repeated groups. For each weak entity type, we create a separate record type defined as member in a set type with as owner the record type on which it is existent dependent. Every 1:N relationship type can be translated to a set type or by the owner or member record type are determined according to the EER cardinalities.
A binary 1:1 relationship type is also modeled using a set type. The owner and member are determined arbitrarily or via existence dependency. We are losing semantics here as we cannot enforce one record member in every set.
· Binary N:M relationship types are not supported in the CODASYL model. Hence, we have to implement them by including a dummy record type. Dummy record types are defined as a member in the 2 sets type and they contain attributes of the relationship type.
· Recursive relationship types are also mapped using an extra dummy record type. It then becomes a member in two set types. Both model an explosion and implosion relationship.
· Ternary relationship types are also not supported in the CODASYL model. Therefore, they need to be implemented by introducing dummy record types which becomes member in three set types.
EER constructs such as specialization, categorization and aggregation are not possible in the CODASYL model and need to be reconstructed using set types which obviously leads to losing semantics.
Ex: superclass or subclass construct. We could create a record type for superclass that becomes owner in set types with subclasses as members. This cannot guarantee that each set contains at most 1 member and cannot indicate the type of specialization (partial or complete, overlap or disjoint). Besides, we can also opt to use one record type that contains the data from the superclass and all the subclasses. A drawback is that it results into loads of empty data fields.
Ex: HR database. The underlined cardinalities are the ones that correspond to the ER model. They cannot be enforced in the CODASYL model. We cannot enforce that a department should have at least one employee or that one department should have at least one manager.
3.2 Mapping an EER model to a relational model

Let’s briefly sum up the key concepts of a relational model :
· It consists out of relations.
· A relation is a set of tuples characterized by attributes.
· A relation has a primary key which uniquely identifies its tuples.
· Relationships can be established by means of foreign keys which refer to primary keys.
· All relations in a relational model are normalised. Such that no redundancies or umbiguities are left in the model.
The first step is to map each entity type into a relation. Simple atribute types can be directly mapped wheareas composite attribute types need to be decomposed into its component attributes. One of the key attribute types of the entity type can be set as the primary key of the relation.

We have two entity types : employee and project. We create relations for them. The employee entity type as 3 attribute types : SSN, address (atomic attribute type), ename which is a composite attribute type consisting of first name and last name. The project entity type also has three attribute types : PNR, pname, pduration. Both key attribute types have been mapped to the primary keys of bith relations. Also note that the ename has been decomposed into first and last name in the relation EMPLOYEE.
Then we create 2 relations for each entity type particpating in a binary 1:1 relationship type. The connection can me made by including a foreign key in one of the relations to the primary key of the other. In case of existence dependancy, we put the foreign key in the existend dependent relation and declare it as NOT NULL. The attributes of the 1:1 relationship type can then be added to the relation with the foreign key.
Let’s consider a “manages” relationship type between employee and department. An employee manages either 0 or 1 departement and a department is manged by 0 or 1 employee. In other words, department is existence dependent from employee. We create relations for both entity types and then add attribute types.
How to map the relationship type ?
A first option would be to add a foreign key “DNR” to the employee relation which refers to the primary key DNR in department. This foreign key can be null since not all employees manage a department.
· Binary 1:N relationships can be mapped by using a froreign key in the relation corresponding to the participating entity type at the N-side of the relationship type.
· The foreign key refers to the primare key of the realtion corresponding to the entity type at the 1-side of the relationship tpye.
Depending upon the minimum cardinality, the foreign key can be defined as NULL or not allowed.
· The attribute types of the 1:N relationship type can be added to the relation corresponding to the participating entity type.
The “works in” relationship type is an example of a 1:N relationship type. An employee works in exactly one department whereas a department can have 1 to N employees working in it. The strating date represnet the date an employee started working in the department. We started by creating the relation EMPLOYEE and DEPARTMENT for both entity types.

There are again two options to map this relationship type into the relational model.
M:N relationship types are mapped by introducing a new relation R. The primary key of R is a combination of foreign keys referring to the primary keys of the relations corresponding to the participating entity types.
The attribute types of these relationship types can also be added to R.
The WORKS ON relationship type is a good example. An employee works on 0:N projects whereas a project is being worked on by 0:M employees. We start by creating relations for both entity tpes. We cannot add a foreign key to the employee relation as it would give as a multivalued attribute type since an employee can work on multiple projects. Likewise, we cannot add a foreign key to the project relation as a project is been worked on by multiple employees. In other words, we need to create a new relation to map the EER relationship type “works on”.
Here we can see the relation WORKS ON defined. It has 2 foreign keys: SSN and PNR which together make up the primary key and can thus not be null. The hours attribute type is also added.

If we changed the assumptions, let’s say that an employee works on at least one project and a project is being worked on by at least one employee. In other words, the minimum cardinalities changed to one on both sides. The solution remains the same. But only 2 of the cardinalities will be enforced.
For each multivalued attribute type, we create a new relation R. We put a multivalued attribute type in R together with a foreign key referring to the primary key of the original relation. Multivalued composite attribute types are again decomposed into their components. The primary key can than be set base upon the assumptions
Phone number is a multivalued attribute type. Indeed, an employee can have multiple phone numbers. We create a new relation EMP-PHONE. It has two attribute types : PhoneNr and SSN. The latter is a foreign key refering to the employee relation. If we assume that each phone number is assigned to only one employee then the attribute type PhoneNr suffises as the primary key of the relation EMP-PHONE.
If a phone number can be shared by multiple employees, this attribute type is no longer appropriated as primary key of the relation. Also SSN cannot be assigned as primary key since an employee can have multiple phone numbers. Hence, the primary key becomes a combination of both phone number and SSN. This illustrates how the business specifics can help to find the primary key of a relation.

RELATIONAL MODEL
EMPLOYEE(SSN, ename, address) EMP-PHONE(PhoneNr, SSN)
RELATIONAL MODEL
EMPLOYEE(SSN, ename, address)
EMP-PHONE(PhoneNr, SSN)
A weak entity type should be mapped in a relation type R with corresponding attributes. A foreign key must be added, referring to the primary key of the relation corresponding to the owner entity type. Because of the existence dependence, the foreign key is declared is NOT NULL. The primary key of R is the combination of the partial key and the foreign key.
Room is a weak entity type which is existent dependent from hotel. We create two relations: HOTEL and ROOM. Room has a foreign key, HNR which is declared as NOT NULL and refers to hotel. Its primary key is the combination of RNR and HNR.

Relational model:
Hotel (HNR, Hname)
Room (RNR, HNR, beds)
To map a n-ary relationship type, we first create relations for each participating entity type. We then also define one additional relation R to represent the n-ary relationship type and add foreign keys to R referring to the primary keys of each of the relations corresponding to the participating entity types. The primary key of R is a combination of all foreign keys. Attribute types of the n-ary relationship can be added to R.
Booking is a ternary relationship type between tourist, hotel and travel agency. It has one attribute type: price. The relational model has relations for each of the three attribute types together with the relation BOOKING for the relationship type. The primary key of the latter is the combination of the three foreign keys. It also includes the price attribute. All six cardinalities are perfectly represented in the relational model.
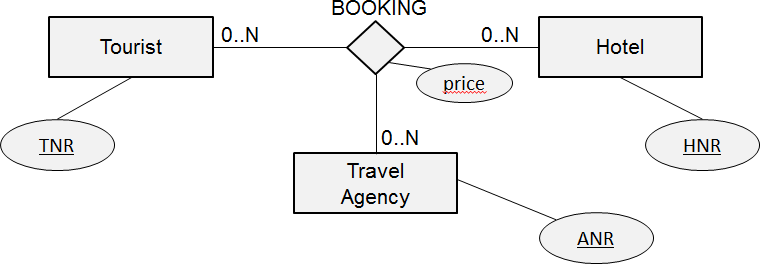
Relational model: TOURIST(TNR, …) TRAV_AGENCY(ANR, …) HOTEL(HNR, …)
BOOKING(TNR, ANR, HNR, price)
Unary or recursive relationship types can be mapped depending upon the cardinality.
· A recursive 1:1 or 1:N relationship type can be implemented by adding a foreign key referring to the primary key of the same relations.
· For a N:M relationship type, a new relation R needs to be created with 2 NOT NULL foreign keys referring to the original relation.
· It is recommended to use role names to clarify the meaning of the foreign keys.

Add a foreign key supervisor the employee relation which refers to its primary key SSN. The foreign key can be null since it is possible that an employee is supervised by 0 other employees. Since the foreign key cannot be multivalued, an employee cannot be supervised by more than one other employee.

A relational model is not a perfect mapping of the EER model. Some of the cardinalities have not been perfectly translated. Indeed, according to the multiple examples used in this section, it cannot be guaranteed that a department has at minimum one employee (not considering the manager). This is the case in the ER model. Besides, the same employee can be manager of multiple deparments. Some of the earlier major shortcomings of the EER model still apply here. We cannot guarantee that a manager of a department also works in the department. And we cannot also enforce that employees should work on projects assigned to departments to which the employees belong.
How could we map some of the EER concepts to the relational model?
· Superclass/subclass relationships
EER specializations can be mapped in various ways. The first option is to create a relation for the superclass and each subclass and link them with foreign keys. Another option is to create a relation for each subclass but not for the superclass. Finally we can create one relation with all attributes from the superclass and subclasses and add a type attribute.

1st option: For this example, we will create three relations, one for the superclass (ARTIST) and two for the subclasses (SINGER and ACTOR). We add a foreign key ANR to each subclassrelation which refers to the superclass relation. This foreign key also serves as primary keys.
/!\ In case de specialization would have been total and not partial, then we wouldn’t have been able to enforce it with this solution. If the specialization would have been disjoint instead of overlapped, again, this wouldn’t have been possible to model it with the first option.
2nd option: The second approach to map an EER model to a relational model is to only map relations for the subclasses. Let’s illustrate this with a total and overlapping example. The attribute types of the superclass have to be added to the subclasses. The problem is that it creates redundancy. Therefore, this is not efficient from a storage perspective. Besides, this second option cannot enforce a relation to be disjoint, since the tuples in both relations can overlap.
3rd option: Another option is to store all the subclass and superclass information in one relation. In this case, we add a type attribute “discipline” to indicate the subclass.

- This approach can generate a lot of NULL values for the subclass specific attribute types.
· Shared subclasses
In a specialization lattice, a subclass can have more than one superclass. Ex: a PHD student is both an employee as well as a student. This can be implemented in the relational model by defining three relations: EMPLOYEE, STUDENT and PHD. The primary key of the latter is a combination of two foreign keys referring to EMPLOYEE and STUDENT. This solution does not allow modeling a total specialization since we cannot enforce that all employees and student tuples are referenced in the PHD-student relation.
Relational model: EMPLOYEE(SSN, …)
STUDENT(SNR, …)
PHD-STUDENT(SSN,SNR,…)

· Categories
Another extension is the concept of a categorization. In this case, the category subclass is a subset of the union of the entities of the super classes. Ex: an account holder can eider be a person or a company. This can be implemented in a relational model by creating a new relation that corresponds to the category and adding the corresponding attributes to it. We then define a new primary key attribute (a surrogate key) for the relation that corresponds to the category. This surrogate key is then added as a foreign key to each relation corresponding to a superclass of the category. In case the super classes have to share the same key attribute types, then this one can be used in there is no need to add a surrogate key.
This solution is not perfect since we cannot guarantee that the tuples of the category relation are a subset of the union of the tuples of the super classes !

Relational model:
PERSON(PNR, …, CustNo)
COMPANY (CNR, …, CustNo)
ACCOUNT-HOLDER (CustNo, …)
· Aggregations
Aggregation is the third extension provided by the EER model.
In this example we aggregated the two entity type’s consultant and project into an aggregation called participation. This aggregation has an attribute type date and participated in a 1 to M relationship type with the attribute type contract.

This can be implemented in the relational model by creating 4 relations: CONSULTANT, PROJECT, PARTICPATION, CONTRACT. The participation relation models the aggregation. Its primary key is the combination of two foreign keys referring to the consultant number and project number.
Mapping an EER model to an OO model
Mapping an EER conceptual model to a logical OO model is unusual since it would have been better to start off with a conceptual OO model. The OO model works with classes and objects. An object is an instance or occurrence of a class. Each class has both attributes and methods. Association types represent relationships between classes. Finally, inheritance and aggregation relationships between classes can be directly modeled.
The OO model offers richer semantics than the EER model and it would be therefore possible to further perfection the conceptual EER model.

In the OO logical model, methos can be added to the classes for further semantics refinements. A method has a method name, input and output argument, together with an implementation or body. This should all be carefully defined together with the business users.
Ex: method “Add-employee” wich allows to add an employee to the employee class. The input argument consists of all the employee data (SSN, date of birth, name, …). The output is void since this method does not return anything.

This model offers more semantics than the EER model.
Mapping an OO model to a CODASYL model
Mapping an OO model to a CODASYL model is about the worst mapping in terms of loss of semantics since we start from the riches conceptual model and implement it as the poorest conceptual model. Mapping like this could take place because of legacy environment

· Lots of loss of semantics ! It is important that it is documented and followed up with application code.
Mapping an OO model to a relational model
This is an approach which is frequently followed in the industry. Two approaches can be adopted here.
· A pure relational approach: maps an OO model to a standard relational model. Relations will be created and foreign keys defined to implement OO concepts such as associations, specialization, categorization and aggregation. Obviously this will involve a lot of semantics. Besides, methods cannot be implemented in a pure relational model.
· Object relation approach: extension of the relational model which add a selection of OO concepts such as named types, collection types, user-defined functions and inheritance.

This mapping is straight forward and may involve only some minor refinements of the model. No loss of semantics is incurred. The OO model can then be implemented in a transparent way using the OO DBMS. OO DBMS are not that popular in the industry due to their intrinsic complexity.
The mapping process can be supported by a case or a Computer Aided Software Engineering tool. This tool allows to automatically converting it to a logical data model. They also provide facilities to document any semantics that may get lost during the translation. The obtained logical data model can be further tailored by making use of DBMS-specific modeling features and constructs to further improve performance or semantic richness.