Once the logical database design has ended, we can continue with the physical database design. The goal of this step is to choose specific storage structures and access paths for the physical database files to achieve good performance for the various database applications. A key input for this step is the characteristics of the programs, transactions and queries which will interact with the database. Ideally, our database implementation should allow for physical data independence whereby changes to the physical design can be made without impact on the logical and external database model and applications.
3 key performance criteria :
· Response time is the time elapsed between submitting a database query and receiving a response. In a stock trading context, the response time is a critical parameter.
· Space utilization refers to the amount of storage space used by the database files and their access path structures on disk. In a big data setting, it should be carefully evaluated.
· Transaction throughput is the average number of transactions that can be processed per minute, per unit of time. Especially important for operational systems.
Another crucial piece of information is the characteristics of the tables and the queries accessing them.
· Characteristics of tables: amount and type of attributes, constraints, access rights, number of rows, estimated size and growth.
· Characteristics of queries: files that will be accessed by the query, attributes on which any selection conditions are specified, attributes on which any join conditions are specified, attributes whose values will be retrieved, frequency of execution, time constraints, amount of select/update/insert/delete queries, characteristics of select/update/insert/delete queries (attributes affected), etc.
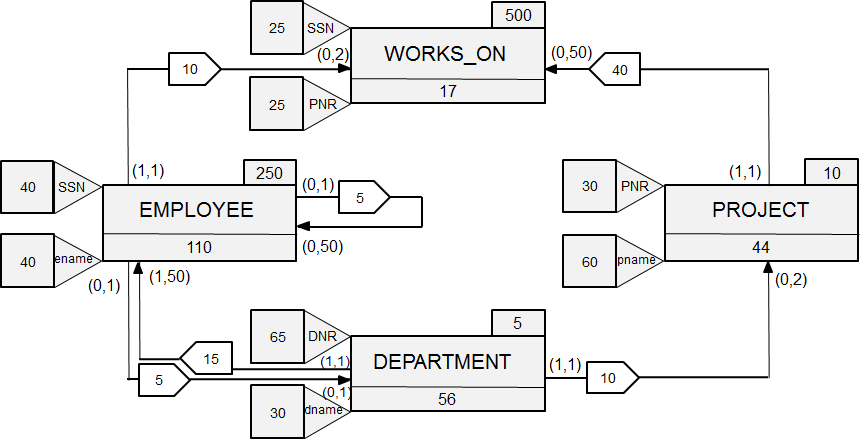
Information displayed about the data size and usage. Rectangles represent the relations. We expect to have 250 employees, 5 departments, 10 projects and 500 works on tuples. Based upon the attributes, it is estimated that an employee tuple consumes 110 bytes of storage. The anticipate access paths have been displayed. In 40% of the cases, employee information will be retrieved through either SSN or employee name, in 5% to the recursive entity type and in 50% through the department.
The average cardinalities have also been added: a department has on average between 1 and 50 employees. We can therefore estimate the storage space is needed and decide upon which access should be defined during this step.
During this step, it might be decided to split up some relations to improve the performance. Consider the relation EMPLOYEE (SSN, ename, streetaddress, city, sex, date of birth, photo, fingerprint, MNR, DNR).This relation contains quite a number of attributes. If it turns out that most applications and/or queries only retrieve the SSN and name of an employee than it might be possible to split the relation into two different relations EMPLOYEE1 (SSN, ename) and EMPLOYEE2(SSN, streetaddress, city, sex, date of birth, photo, signature, MNR, DNR). The first relation can then be used to serve the bulk of the application send to queries. In case all information needs to be retrieved, then both relations will have to be joined. Also denormalization might be considered to speed up the response time of database queries.
Suppose that many applications ask information about which employees work on what project. Each time, the number and name of employees asked for together with the number and name of the project. For a normalized database scheme, this would imply that the works on relationship needs to be joined with employee and project which is a resource intense operation. Hence, it might be considered to denormalize the data definitions by adding the employee name and project name attributes to the works on relation. This will allow for faster retrieval for requirements.
Consequence: inefficient use of storage and resulting anomalies.
In a distributed environment, it needs to be decided which data will be stored where and on what storage media. Tables need to be assigned to tables spaces which are then assigned to physical files stored on network resources. Related tuples can be physically clustered on an adjacent disk block to improve response time. Various types of indexing can also be added. An index represents a fast access path to the physical data. In a RDBMS environment, unique indexes will be automatically defined for the primary keys. Optional indexes can be designed for foreign keys or non-key columns that are often used as query selection criteria.
Cluster indexes can be created where the index order matches the physical order on disk.
A next step is to start preparing the data definition language or DDL statements for :
§ Table definitions
§ Definition of primary keys and declaration of integrity and uniqueness constraints
§ Definition of foreign keys and declaration of referential integrity constraints
§ Definition of the other columns and “NOT NULL" declarations
§ Special integrity constraints: check constraints, triggers
§ Definition of views
§ Security privileges (read/write access)
§ Output of this step are the DDL statements
The resulting DDL statements will then be compiled by the DDL compiler such that the data definitions can be stored in a catalog of the RDBMS. The outcome of this will be a database scheme and a collection of empty database files. The latter can then be loaded or populated with data. The database can now be accessed by application programmers by using data manipulation language (DML statements). The performance of the DML operations will be continuously monitored by storing performance at this six such as response time, space utilization, transaction throughput raise in the catalog, etc. This will allow to carefully fine-tuning the performance of the database by optimizing indexes, database design and queries themselves.