Explain about Lossless Predictive Coding
Lossless Predictive Coding:
The error-free compression approach does not require decomposition of an image into a collection of bit planes. The approach, commonly referred to as lossless predictive coding, is based on eliminating the interpixel redundancies of closely spaced pixels by extracting and coding only the new information in each pixel. The new information of a pixel is defined as the difference between the actual and predicted value of that pixel.
Figure shows the basic components of a lossless predictive coding system. The system consists of an encoder and a decoder, each containing an identical predictor. As each successive pixel of the input image, denoted fn, is introduced to the encoder, the predictor generates the anticipated value of that pixel based on some number of past inputs.
The output of the predictor is then rounded to the nearest integer, denoted f^n and used to form the difference or prediction error which is coded using a variable-length code (by the symbol encoder) to generate the next element of the compressed data stream.
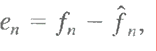

Fig. A lossless predictive coding model: (a) encoder; (b) decoder
The decoder of Fig. 8.1 (b) reconstructs en from the received variable-length code words and performs the inverse operation
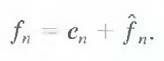
Various local, global, and adaptive methods can be used to generate f^n. In most cases, however, the prediction is formed by a linear combination of m previous pixels. That is,

where m is the order of the linear predictor, round is a function used to denote the rounding or nearest integer operation, and the αi, for i = 1,2,..., m are prediction coefficients. In raster scan applications, the subscript n indexes the predictor outputs in accordance with their time of occurrence.
That is, fn, f^n and en in Eqns. above could be replaced with the more explicit notation f (t), f^(t), and e (t), where t represents time. In other cases, n is used as an index on the spatial coordinates and/or frame number (in a time sequence of images) of an image. In 1-D linear predictive coding, for example, Eq. above can be written as
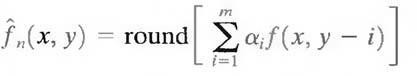
where each subscripted variable is now expressed explicitly as a function of spatial coordinates x and y. The Eq. indicates that the 1-D linear prediction f(x, y) is a function of the previous pixels on the current line alone.
In 2-D predictive coding, the prediction is a function of the previous pixels in a left-to-right, top-to-bottom scan of an image.
In the 3-D case, it is based on these pixels and the previous pixels of preceding frames.
Equation above cannot be evaluated for the first m pixels of each line, so these pixels must be coded by using other means (such as a Huffman code) and considered as an overhead of the predictive coding process. A similar comment applies to the higher-dimensional cases.